
Synapse Consumption
Synapse Analytics Consumption Patterns
This blog focusses on how could you expose your data using Synapse Analytics. I would first recommend you to have a quick read on Jovan’s Blog and Piethein’s Blog on workspace design considerations.
The dicussion topic for this blog follows the choice which is made for Workspace organisation. This concerns data consumption patterns on the modern lake house architecture on Azure.
Lets assume a company named Contoso. Contoso is headquartered in Europe and has branch offices in Americas , APAC.
The company is building their lake house architecture on Azure.
Based on the Data Management & Analytics Scenario practises , lets assume this setup.
In this setup we have a data management subscription ( Blue Circle) , which is a central data platform team responsible for :
- Providing Skeleton for Infrastructure for Branches to build on
- Making sure governance is in check (non-negotiables) , using azure policies
- Providing Interfaces / Best practises for teams to leverage
- Sample DevOps Pipeleines / DataOps Pipelines for Teams to leverage and build on
- Data Project Templates which could be used by teams / branches
Assuming this team is funded by the headquarters , we have this subscription in Europe.
Other landing zones deployed in wave 1 are :
- EMEA
- AMERICAS
- Global Finance
- Global HR
Scenario :
Let us assume APAC HR team wants to use data stored in the global HR systems for use case A. The Global HR team , has data as an Employee Entity , not only for the APAC region , but the whole of Contoso. Due to heavy regulations (GDPR) , it is crucial to only let APAC see thier own data and not of any other region , which could lead to heavy penalties and fines.
Consumption Patterns
As any other company , contoso has requirements for all 3 consumption modes :
- Batch Mode
- API Mode
- Streaming Mode
Batch Mode
The most commonly used pattern at contoso , even today is batch mode. More than 80% of data analytics at contoso is done using the batch mode.
A typical Data warehousing pattern is adopted here too . Usual suspects of Data Loading from On premises , CRM systems and third party DaaS (Data As a Service Providers).
Data Processing is done using an ELT approach and served in the consumption zone.
For this blog we will focus on the consumption part , we will have a seperate blog which discusses the data processing options on the Lake house pattern on Azure.
So to keep it short , assume the data is on the consumption zone ready for teams / reporting layers to consume.
Majority of data access on the lake for the initial stages is served from this pattern. Historically batch data is provided as extracts on a schedule ( monthly/weekly/daily/hourly) or on an event based trigger.
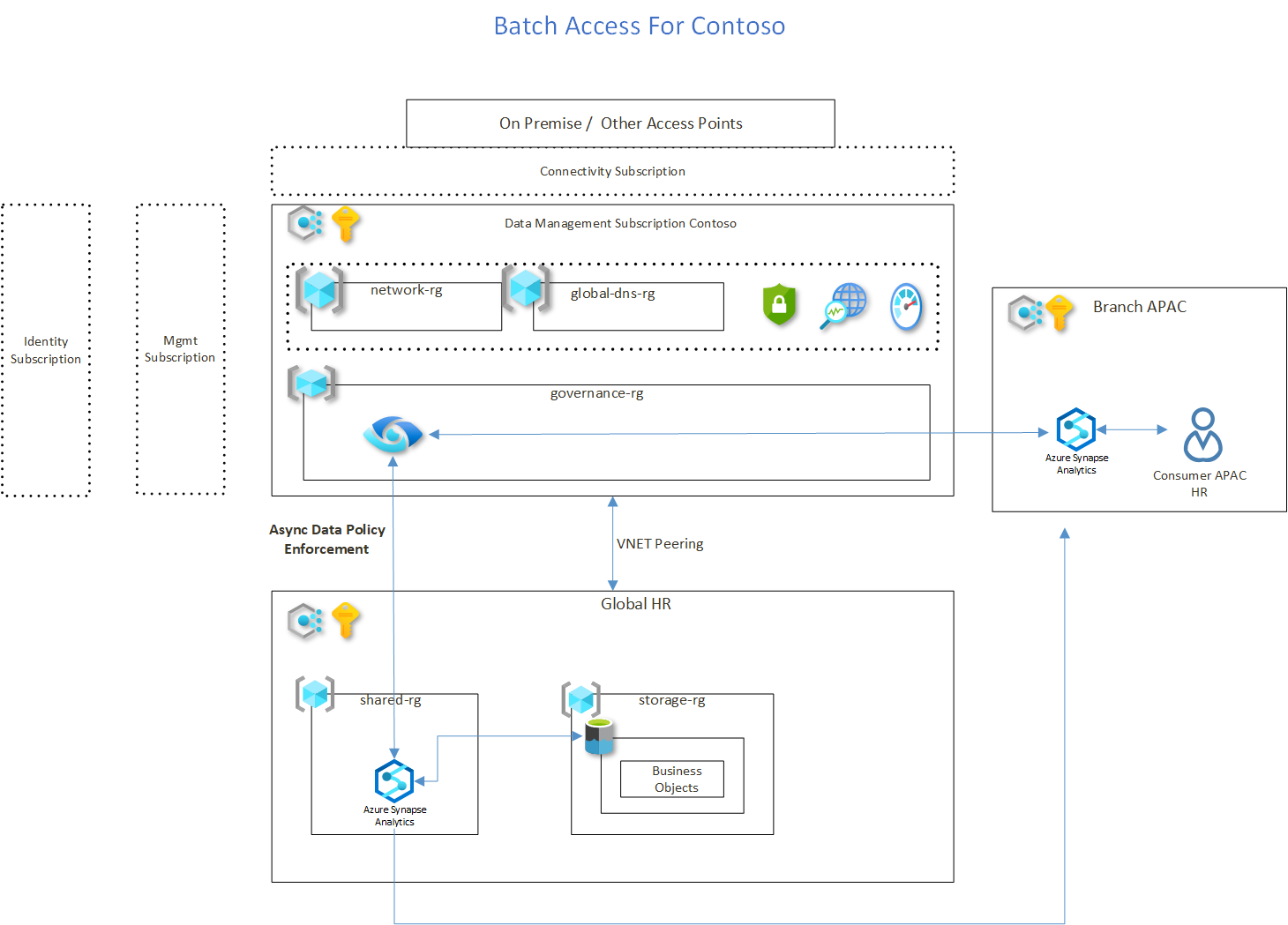
Flow Explained For Batch
This architecture represents the data access pattern mapped to an azure data plaform. The dotted rectangles in the picture , represent core subscriptions.
These are :
- Identity
- Management
- Connectivity
- Networking
This is based on the enterprise scale landing zone recommendation. The assumption is that ESLZ has been followed at contoso and the core cloud platform team has already deployed these subscrptions and the base platform is ready to be built.
The Data Platform team , builds on top of the ESLZ setup. A dedicated data managment subscription , named Data Management Subscription Contoso has been setup.
This subscription , hosts multiple resource groups :
- network-rg ( for networking related resources)
- global-dns-rg
- governance-rg (for data governance resoruces)
This is based on the Data Management & Analytics Scenario recommendations
Two Subscriptions are considered in this flow as an example. These are represented on the right and bottom of the data management subscription.
APAC and Global HR (in Europe) are two subscriptions involved in this data access scenario.
Both these subscriptions are goverened by the central Data Management Contoso Subscription.
In order to get this setup working , these are the steps followed :
- Azure purview is setup in the data management subscription , inside the governance-rg resource group.
- Global HR setups a consumption zone , where the business objects ( in this case Employee Entity) / Entities are loaded based on an SLA on data quality and availability . This could be a consumption folder on the storage account provisioned inside the storage-rg resource group.
- A view (Synapse Serverless View) is created on top of this entity (Employee).
- Create a Role Based Access Control / Row Level Security on the view which can meet the governance rule we have explained earlier ( in the scenario section).
- Purview is going to scan the serverless view and the storage entity ( Employee) and the metadata rolls up to purview.
- Now the metadata is available and published for other branches to find.
Access Pattern For Branch in Batch Mode
Once the data is registered in the catalog , the next step is for the branch to find the data they are interested in.
Steps explained :
- Branch Persona , business analyst / data anlayst is using his tool for data analysis. In this case , APAC is using azure synapse. Purview is natively integrated into synapse , so the user will search for this entity (Employee) in the central catalog , to find where does this data exist.

- Purview returns the metadata and location information of the Employee Entity . The BA / DA could explore the metadata and then directly access this live view , where the data sits. link
- The BA / DA will fire the select * from Employee ( View)
- The RLS aka Row Level Security, which is applied on the serverless view kicks in and only returns the values which the APAC BA / DA are eligible to view.
To be specific , as an example lets says contoso has 5 Million customers worldwide. APAC has 2 Million customers in this mix , so the current setup should only return the 2 Million rows.
API Mode
This is to accommodate API access to datasets on the data lake (In this case Employee Entity).
The idea is to expose business objects as APIs for teams to consume. This supports the microservices approach , where the data is offered as a product via APIs.
Versions /Quality and documentation of the APIs are the responsibility of the data owners. This information needs to be registered centrally and should be available for other teams to search for which is done via Purview in this case. Automated process for granting access control to data needs to be in place.
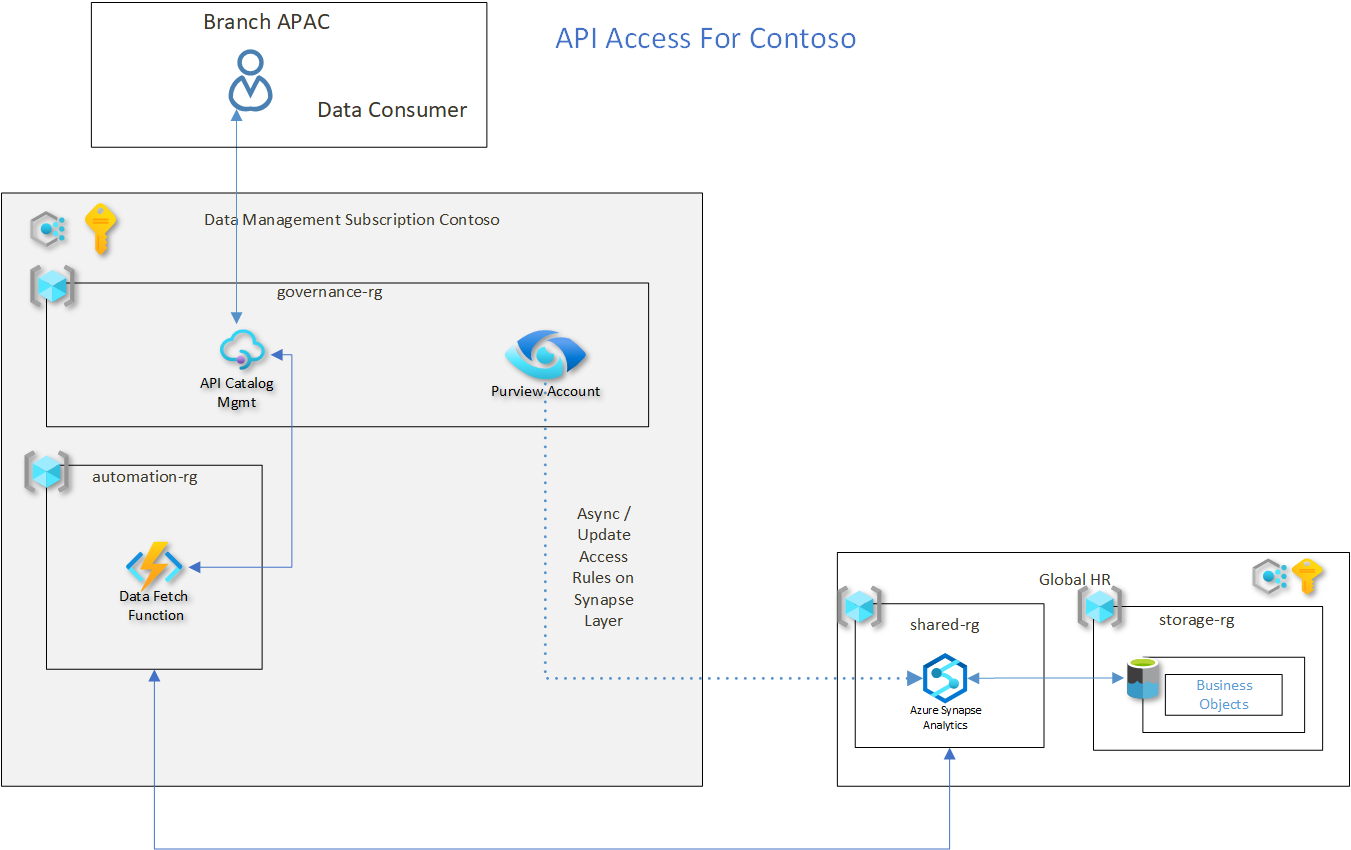
Flow Explained For API Access
Setup
Three subscriptions are in place for this example. There is one central data management subscription. Similar to the previous setup there is a governance-rg (resource group) in which there are two resources.
- API Managment Layer ( For registering APIs for data on Serverless Views)
- Azure Purview (For Catalog and Access Management)
Steps for API Data Access
To continue with the story of APAC HR data access from the global HR platform. Consider that the steps* mentioned ealier are completed ( Purview Scan and data entity registration).
There is an additional step / custom work which the data managment team needs to build.
In order to build an API layer on top of the data entity an Azure function is created.
This function needs to take the input database (on serverless) , and entity (on serverless) name as parameters which fire a query onto the serverless layer.
There needs to be a second action ( in this case a stored procedure on the serverless side) , which would be triggered during the call and should return the json / payload.
This Azure function , should be able to pass the identity of the user / application requesting the call to the serverless layer. ( This assumes only AAD access is permited on the Synapse Layer)
As soon as purview scans the new resource this flow should be applicable automatically since the function and the Stored procedure are utilities which would be existing on the central platform and the workspace.
Access Pattern For Branch in API Mode
- Branch Persona , Application user / Data Analyst search for this data on pruview (Employee)
-
Purview returns the metadata and location information of the Employee Entity . The BA / DA could explore the metadata and then directly access this live view , where the data sits.
-
The BA / DA will fire the query(GET call) using a client of choice , for ex. postman , with database name and entity name as parameters . For This example , database name = “hr_erp” and entity name = “employee”
-
The request first hits an API Managment Layer where the API is registered.
-
The Azure Function Registered with the API Management layer is triggered with the parameters passed (database name and entity name)
-
The Function in turn triggers a stored procedure on the global hr Synapse analytics workspace.
-
This Stored procedure , executes the select * on Employee View , which has Row Level Security applied to it.
-
Stored Procedure returns only the Employee values which APAC is supposed to see in the return Payload.
-
Azure Function returns back the data as a payload requested by the client ( Branch APAC)
** For large datasets concepts like pagination have to be applied / option to do a bulk load by dynamically generating an Syanpse Pipeliene based on thresholds could be considered.